Using Data Parallel Cloud Flows to Analyze Historical Event Data
In this example, you learn how to use data parallel cloud flows with historical event data at scale. The data is drawn directly from open government data on the internet. This sample has been adapted from Isaac Abraham's blog.
You start by using FSharp.Data and its CSV Type Provider. Usually the type provider can infer all data types and columns but in this case the file does not include headers, so we’ll supply them ourselves. You use a local version of the CSV file which contains a subset of the data (the live dataset even for a single month is > 10MB)
1:
|
|
With that, you have a strongly-typed way to parse CSV data.
Here is the input data. (Each of these files is ~70MB but can take a significant amount of time to download due to possible rate-limiting from the server).
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: |
|
Now, stream the data source from the original web location and across the cluster, then convert the raw text to our CSV provided type. Entries are grouped by month and the average price for each month is computed.
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: |
|
A CloudFlow is an MBrace primitive which allows a distributed set of transformations to be chained together. A CloudFlow pipeline is partitioned across the cluster, making full use of resources available: only when the pipelines are completed in each partition are they aggregated together again.
Now observe the progress. Time will depend on download speeds to your data center or location.
For the large data sets above you can expect approximately 2 minutes.
While you're waiting, notice that you're using type providers in tandem with cloud computations.
Once we call the ParseRows function, in the next call in the pipeline,
we’re working with a strongly-typed object model – so DateOfTransfer is a proper DateTime etc.
For example, if you hit "." after "row" you will see the available information
includes Locality, Price, Street, Postcode and so on.
In addition, all dependent assemblies have automatically been shipped with MBrace.
MBrace wasn’t explicitly designed to work with FSharp.Data and F# type providers – it just works.
Now wait for the results.
1: 2: 3: 4: |
|
Now that you have a summary array of year, month and price data, you can chart the data.
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: |
|
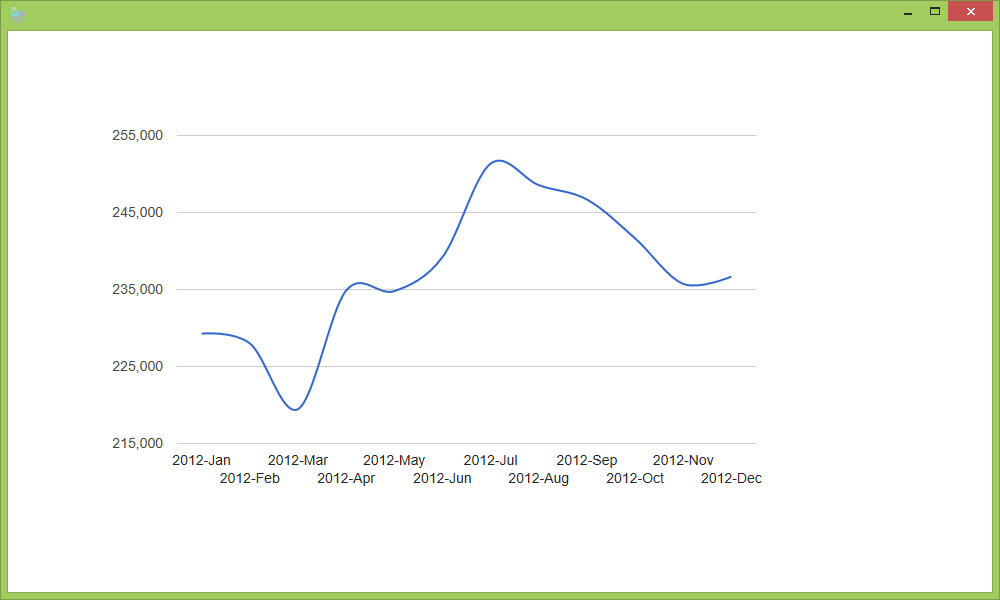
Persisted Cloud Flows
To prevent repeated work, MBrace supports something called Persisted Cloud Flows (known in the Spark world as RDDs). These are flows whose results are partitioned and cached across the cluster, ready to be re-used again and again. This is particularly useful if you have an intermediary result set that you wish to query multiple times.
In this case, you now persist the first few lines of the computation (which involves downloading the data from source and parsing with the CSV Type Provider), ready to be used for any number of strongly-typed queries we might have: –
1: 2: 3: 4: 5: 6: 7: |
|
Now observe progress:
1: 2: |
|
Now wait for the results:
1:
|
|
The input file will have been partitioned depending on the number of workers in your cluster. The partitions are already assigned to different workers. With the results persisted on the nodes, we can use them again and again.
First, get the total number of entries across the partitioned, persisted result:
1: 2: 3: 4: |
|
Next, get the first 100 entries:
1: 2: 3: 4: 5: |
|
Next, get the average house price by year/month.
1: 2: 3: 4: 5: 6: 7: 8: |
|
Make a chart of the results. This will be the same chart as before, but based on persisted results.
1: 2: 3: 4: 5: 6: |
|
Next, get the average prices per street. This takes a fair while since there are a lot of streets. We persist the results: CloudFlow.cache is the same as persiting to memory.
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: |
|
Next, use the cached results to get the most expensive city and street.
1: 2: 3: 4: 5: |
|
Next, use the cached results to also get the least expensive city and street.
1: 2: 3: 4: 5: |
|
Count the sales by city:
1: 2: 3: 4: 5: 6: 7: 8: |
|
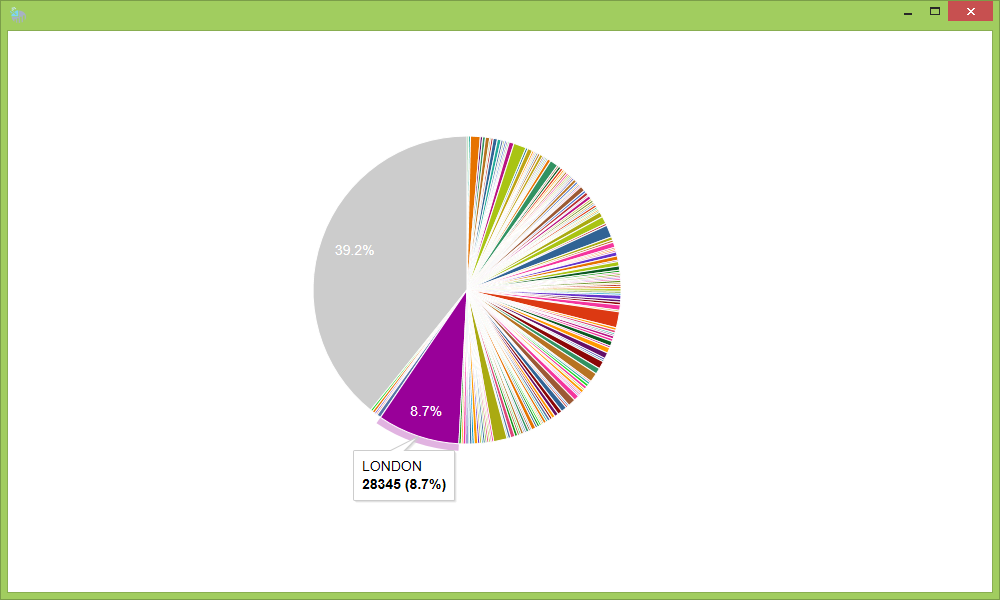
And so on.
So notice that the first query takes 45 seconds to execute, which involves downloading the data and parsing it via the CSV type provider. Once we’ve done that, we persist it across the cluster in memory – then we can re-use that persisted flow in all subsequent queries, each of which just takes a few seconds to run.
Finding the Current Prices of Monopoly Streets
We all know and love the game Monopoly. For those who grew up in the United Kingdom or Australia, you probably played using the London street names and prices where buying Mayfair cost £400. But how do prices today look, and which streets are now the most expensive?
Next, you get the list of all streets on the Monopoly board using the HTML type provider over this web page. This is a type provider in FSharp.Data that helps you crack the content of HTML tables.
1: 2: 3: 4: |
|
This page contains a particular table with all the property names for the UK edition of Monopoly:
1:
|
|
Giving:
1: 2: 3: 4: 5: |
|
Next you put the names into a set, converting them to lower case as you go:
1: 2: 3: 4: 5: 6: 7: 8: 9: |
|
Next, you find the sales that correspond to Monopoly streets, again reusing your calculation of average-prices on streets:
1: 2: 3: 4: 5: 6: 7: |
|
You're done! If you are using the large 4-year data set, you will see this:
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: |
|
Some of these results are false: they are probably not the streets being referred to in the Monopoly game! But most are accurate. You will see that the "red" set does particularly well in the 21st century!! Also, many of the "cheap" properties are still at the lower end of the list, albeit at roughly 7,000x the price of the original game!
Summary
In this example, you've learned how to use data parallel cloud flows with historical event data drawn directly from the internet. By using F# type providers (FSharp.Data) plus a sample of the data you have given strong types to your information. You then learned how to persist partial results and to calculate averages and sums of groups of the data.
Continue with further samples to learn more about the MBrace programming model.
Note, you can use the above techniques from both scripts and compiled projects. To see the components referenced by this script, see ThespianCluster.fsx or AzureCluster.fsx.
from XPlot
namespace FSharp
--------------------
namespace Microsoft.FSharp
namespace FSharp.Data
--------------------
namespace Microsoft.FSharp.Data
Full name: 200-house-data-analysis-example.cluster
Full name: Config.GetCluster
Gets or creates a new Thespian cluster session.
Full name: 200-house-data-analysis-example.HousePrices
Full name: FSharp.Data.CsvProvider
<summary>Typed representation of a CSV file.</summary>
<param name='Sample'>Location of a CSV sample file or a string containing a sample CSV document.</param>
<param name='Separators'>Column delimiter(s). Defaults to `,`.</param>
<param name='InferRows'>Number of rows to use for inference. Defaults to `1000`. If this is zero, all rows are used.</param>
<param name='Schema'>Optional column types, in a comma separated list. Valid types are `int`, `int64`, `bool`, `float`, `decimal`, `date`, `guid`, `string`, `int?`, `int64?`, `bool?`, `float?`, `decimal?`, `date?`, `guid?`, `int option`, `int64 option`, `bool option`, `float option`, `decimal option`, `date option`, `guid option` and `string option`.
You can also specify a unit and the name of the column like this: `Name (type<unit>)`, or you can override only the name. If you don't want to specify all the columns, you can reference the columns by name like this: `ColumnName=type`.</param>
<param name='HasHeaders'>Whether the sample contains the names of the columns as its first line.</param>
<param name='IgnoreErrors'>Whether to ignore rows that have the wrong number of columns or which can't be parsed using the inferred or specified schema. Otherwise an exception is thrown when these rows are encountered.</param>
<param name='SkipRows'>SKips the first n rows of the CSV file.</param>
<param name='AssumeMissingValues'>When set to true, the type provider will assume all columns can have missing values, even if in the provided sample all values are present. Defaults to false.</param>
<param name='PreferOptionals'>When set to true, inference will prefer to use the option type instead of nullable types, `double.NaN` or `""` for missing values. Defaults to false.</param>
<param name='Quote'>The quotation mark (for surrounding values containing the delimiter). Defaults to `"`.</param>
<param name='MissingValues'>The set of strings recogized as missing values. Defaults to `NaN,NA,N/A,#N/A,:,-,TBA,TBD`.</param>
<param name='CacheRows'>Whether the rows should be caches so they can be iterated multiple times. Defaults to true. Disable for large datasets.</param>
<param name='Culture'>The culture used for parsing numbers and dates. Defaults to the invariant culture.</param>
<param name='Encoding'>The encoding used to read the sample. You can specify either the character set name or the codepage number. Defaults to UTF8 for files, and to ISO-8859-1 the for HTTP requests, unless `charset` is specified in the `Content-Type` response header.</param>
<param name='ResolutionFolder'>A directory that is used when resolving relative file references (at design time and in hosted execution).</param>
<param name='EmbeddedResource'>When specified, the type provider first attempts to load the sample from the specified resource
(e.g. 'MyCompany.MyAssembly, resource_name.csv'). This is useful when exposing types generated by the type provider.</param>
Full name: 200-house-data-analysis-example.smallSources
Full name: 200-house-data-analysis-example.bigSources
Full name: 200-house-data-analysis-example.tinySources
Full name: 200-house-data-analysis-example.sources
Full name: 200-house-data-analysis-example.pricesTask
module CloudFlow
from MBrace.Flow
--------------------
module CloudFlow
from Utils
--------------------
type CloudFlow =
static member OfArray : source:'T [] -> CloudFlow<'T>
static member OfCloudArrays : cloudArrays:seq<#CloudArray<'T>> -> LocalCloud<PersistedCloudFlow<'T>>
static member OfCloudCollection : collection:ICloudCollection<'T> * ?sizeThresholdPerWorker:(unit -> int64) -> CloudFlow<'T>
static member OfCloudDirectory : dirPath:string * serializer:ISerializer * ?sizeThresholdPerCore:int64 -> CloudFlow<'T>
static member OfCloudDirectory : dirPath:string * ?deserializer:(Stream -> seq<'T>) * ?sizeThresholdPerCore:int64 -> CloudFlow<'T>
static member OfCloudDirectory : dirPath:string * deserializer:(TextReader -> seq<'T>) * ?encoding:Encoding * ?sizeThresholdPerCore:int64 -> CloudFlow<'T>
static member OfCloudDirectoryByLine : dirPath:string * ?encoding:Encoding * ?sizeThresholdPerCore:int64 -> CloudFlow<string>
static member OfCloudFileByLine : path:string * ?encoding:Encoding -> CloudFlow<string>
static member OfCloudFileByLine : paths:seq<string> * ?encoding:Encoding * ?sizeThresholdPerCore:int64 -> CloudFlow<string>
static member OfCloudFiles : paths:seq<string> * serializer:ISerializer * ?sizeThresholdPerCore:int64 -> CloudFlow<'T>
...
Full name: MBrace.Flow.CloudFlow
--------------------
type CloudFlow<'T> =
interface
abstract member WithEvaluators : collectorFactory:LocalCloud<Collector<'T,'S>> -> projection:('S -> LocalCloud<'R>) -> combiner:('R [] -> LocalCloud<'R>) -> Cloud<'R>
abstract member DegreeOfParallelism : int option
end
Full name: MBrace.Flow.CloudFlow<_>
static member CloudFlow.OfHttpFileByLine : url:string * ?encoding:Text.Encoding -> CloudFlow<string>
Full name: MBrace.Flow.CloudFlow.collect
val averageByKey : keyProjection:('T -> 'Key) -> valueProjection:('T -> 'Value) -> source:CloudFlow<'T> -> CloudFlow<'Key * 'Value> (requires equality and member ( + ) and member get_Zero and member DivideByInt)
Full name: MBrace.Flow.CloudFlow.averageByKey
--------------------
val averageByKey : keyf:('T -> 'Key) -> valf:('T -> 'Val) -> x:CloudFlow<'T> -> CloudFlow<'Key * 'Val> (requires equality and member ( + ) and member get_Zero and member DivideByInt)
Full name: Utils.CloudFlow.averageByKey
val float : value:'T -> float (requires member op_Explicit)
Full name: Microsoft.FSharp.Core.Operators.float
--------------------
type float = Double
Full name: Microsoft.FSharp.Core.float
--------------------
type float<'Measure> = float
Full name: Microsoft.FSharp.Core.float<_>
Full name: MBrace.Flow.CloudFlow.sortBy
Full name: Microsoft.FSharp.Core.Operators.fst
Full name: MBrace.Flow.CloudFlow.toArray
Full name: 200-house-data-analysis-example.prices
Full name: 200-house-data-analysis-example.formatYearMonth
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.sprintf
type DateTime =
struct
new : ticks:int64 -> DateTime + 10 overloads
member Add : value:TimeSpan -> DateTime
member AddDays : value:float -> DateTime
member AddHours : value:float -> DateTime
member AddMilliseconds : value:float -> DateTime
member AddMinutes : value:float -> DateTime
member AddMonths : months:int -> DateTime
member AddSeconds : value:float -> DateTime
member AddTicks : value:int64 -> DateTime
member AddYears : value:int -> DateTime
...
end
Full name: System.DateTime
--------------------
DateTime()
(+0 other overloads)
DateTime(ticks: int64) : unit
(+0 other overloads)
DateTime(ticks: int64, kind: DateTimeKind) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, calendar: Globalization.Calendar) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int, kind: DateTimeKind) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int, calendar: Globalization.Calendar) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int, millisecond: int) : unit
(+0 other overloads)
DateTime(year: int, month: int, day: int, hour: int, minute: int, second: int, millisecond: int, kind: DateTimeKind) : unit
(+0 other overloads)
Full name: 200-house-data-analysis-example.chartPrices
from Microsoft.FSharp.Collections
Full name: Microsoft.FSharp.Collections.Seq.map
static member Annotation : data:seq<#seq<DateTime * 'V * string * string>> * ?Labels:seq<string> * ?Options:Options -> GoogleChart (requires 'V :> value)
static member Annotation : data:seq<DateTime * #value * string * string> * ?Labels:seq<string> * ?Options:Options -> GoogleChart
static member Area : data:seq<#seq<'K * 'V>> * ?Labels:seq<string> * ?Options:Options -> GoogleChart (requires 'K :> key and 'V :> value)
static member Area : data:seq<#key * #value> * ?Labels:seq<string> * ?Options:Options -> GoogleChart
static member Bar : data:seq<#seq<'K * 'V>> * ?Labels:seq<string> * ?Options:Options -> GoogleChart (requires 'K :> key and 'V :> value)
static member Bar : data:seq<#key * #value> * ?Labels:seq<string> * ?Options:Options -> GoogleChart
static member Bubble : data:seq<string * #value * #value * #value * #value> * ?Labels:seq<string> * ?Options:Options -> GoogleChart
static member Bubble : data:seq<string * #value * #value * #value> * ?Labels:seq<string> * ?Options:Options -> GoogleChart
static member Bubble : data:seq<string * #value * #value> * ?Labels:seq<string> * ?Options:Options -> GoogleChart
static member Calendar : data:seq<DateTime * #value> * ?Labels:seq<string> * ?Options:Options -> GoogleChart
...
Full name: XPlot.GoogleCharts.Chart
static member Chart.Line : data:seq<#key * #value> * ?Labels:seq<string> * ?Options:Options -> GoogleChart
type Options =
new : unit -> Options
member ShouldSerializeaggregationTarget : unit -> bool
member ShouldSerializeallValuesSuffix : unit -> bool
member ShouldSerializeallowHtml : unit -> bool
member ShouldSerializealternatingRowStyle : unit -> bool
member ShouldSerializeanimation : unit -> bool
member ShouldSerializeannotations : unit -> bool
member ShouldSerializeannotationsWidth : unit -> bool
member ShouldSerializeareaOpacity : unit -> bool
member ShouldSerializeavoidOverlappingGridLines : unit -> bool
...
Full name: XPlot.GoogleCharts.Configuration.Options
--------------------
new : unit -> Options
static member Chart.Show : chart:GoogleChart -> unit
Full name: 200-house-data-analysis-example.persistedHousePricesTask
Full name: MBrace.Flow.CloudFlow.persist
Full name: 200-house-data-analysis-example.persistedHousePrices
Full name: 200-house-data-analysis-example.count
Full name: MBrace.Flow.CloudFlow.length
Full name: 200-house-data-analysis-example.first100
Full name: MBrace.Flow.CloudFlow.take
Full name: 200-house-data-analysis-example.pricesByMonthTask
Full name: 200-house-data-analysis-example.pricesByMonth
Full name: 200-house-data-analysis-example.averagePricesTask
Full name: MBrace.Flow.CloudFlow.cache
Full name: 200-house-data-analysis-example.averagePrices
Full name: 200-house-data-analysis-example.mostExpensive
Full name: MBrace.Flow.CloudFlow.sortByDescending
Full name: Microsoft.FSharp.Core.Operators.snd
Full name: 200-house-data-analysis-example.leastExpensive
Full name: 200-house-data-analysis-example.purchasesByCity
Full name: MBrace.Flow.CloudFlow.countBy
Full name: 200-house-data-analysis-example.MonopolyTable
Full name: FSharp.Data.HtmlProvider
<summary>Typed representation of an HTML file.</summary>
<param name='Sample'>Location of an HTML sample file or a string containing a sample HTML document.</param>
<param name='PreferOptionals'>When set to true, inference will prefer to use the option type instead of nullable types, `double.NaN` or `""` for missing values. Defaults to false.</param>
<param name='IncludeLayoutTables'>Includes tables that are potentially layout tables (with cellpadding=0 and cellspacing=0 attributes)</param>
<param name='MissingValues'>The set of strings recogized as missing values. Defaults to `NaN,NA,N/A,#N/A,:,-,TBA,TBD`.</param>
<param name='Culture'>The culture used for parsing numbers and dates. Defaults to the invariant culture.</param>
<param name='Encoding'>The encoding used to read the sample. You can specify either the character set name or the codepage number. Defaults to UTF8 for files, and to ISO-8859-1 the for HTTP requests, unless `charset` is specified in the `Content-Type` response header.</param>
<param name='ResolutionFolder'>A directory that is used when resolving relative file references (at design time and in hosted execution).</param>
<param name='EmbeddedResource'>When specified, the type provider first attempts to load the sample from the specified resource
(e.g. 'MyCompany.MyAssembly, resource_name.html'). This is useful when exposing types generated by the type provider.</param>
Full name: 200-house-data-analysis-example.monopolyPage
Full name: 200-house-data-analysis-example.data
Full name: 200-house-data-analysis-example.monopolyStreets
String.ToLower(culture: Globalization.CultureInfo) : string
Full name: Microsoft.FSharp.Core.ExtraTopLevelOperators.set
Full name: 200-house-data-analysis-example.monopoly
Full name: MBrace.Flow.CloudFlow.filter

